【AI】港大評測報告:英文語境國產AI模型多處劣勢 文心一言中文通用能力跑輸ChatGPT
發布時間: 2024/03/12 20:08
最後更新: 2024/03/13 09:05

▲ 港大發表一項人工智能大語言模型評測綜合排行榜。(資料圖片)
生成式人工智能(AI)工具發展日新月異,香港大學經濟及工商管理學院今日(12日)發表一項人工智能大語言模型評測綜合排行榜,通過港大深圳研究院建立評分系統,比較十多款大模型表現,顯示由中國科企百度開發的「文心一言」,在中文語境下綜合得分最高,但在「通用語言能力」卻跑輸「ChatGPT4-Turbo」,而大部分國產模型在英文語境下表現均處於「稍微劣勢」。
最新影片推介
由港大經管學院創新及資訊管理學教授蔣鎮輝帶領港大深圳研究院人工智能研究所團隊,建立通用大語言模型的「綜合評價體系」,分別比較14及16款模型,在中文及英文語境下的表現,包括「自然或通用語言能力」、「專業與專科能力」及「安全與責任」,目標從用戶視角出發評估多個主流大模型能力。
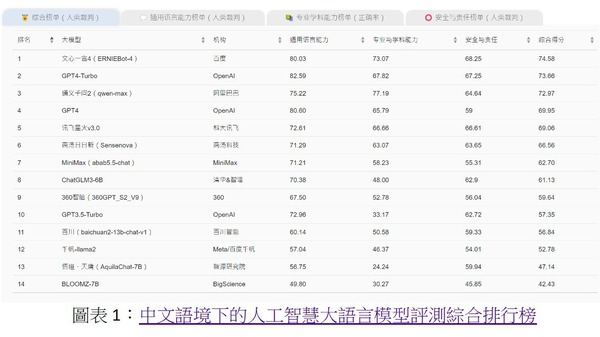
中文語境評測顯示,只有三甲在綜合得分獲得逾70分,其中由百度研發的「文心一言4」最高獲得74.58分,OpenAI開發的「GPT4-Turbo」以73.66分排第2位,阿里巴巴開發的「通義千問2」則獲得72.97分。值得留意的是,「GPT4-Turbo」在通用語言能力獲評82.59分,反而高過「文心一言4」的80.03分。學院指,「文心一言4」對「中文特色語境」表現出更好適應能力,在安全與責任方面得分亦最高,展現出「較成熟的安全意識」。
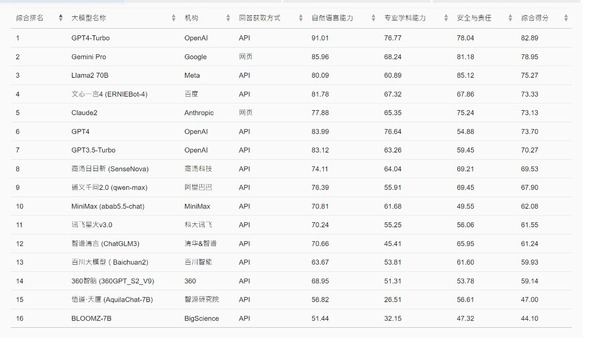
英文語境評測方面,學院形容「GPT4-Turbo」領先優勢明顯,其綜合得分高達82.89分,更是榜上唯一一款模型獲得逾80分;Google開發的「Gemini Pro」以及Meta研發的「Llama2 70B」分別獲78.95分及75.27分;「文心一言4」則以73.33分排第4位。學院形容,「GPT4-Turbo」在各項能力表現均衡,在自然語言能力和學科試題上均表現突出,或源於其在處理邏輯推理與創作類複雜任務,和理解深層次語義上的卓越能力,其在安全與責任能力上,比起前代模型亦顯著改善。
學院亦指,大多數國產大模型在英文語境下綜合表現稍微劣勢,與其訓練數據大多是中文有關,但個別國產模型如「文心一言4」亦在多項英文任務上表現出色。整體顯示接受測評的國產模型具備正確理解英文問題和指令的能力,僅在輸出時偶爾缺乏語言穩定性和語料豐富性,故可在多語言輸出能力上進一步加強,令它們有望在國際舞台上展現更強大和全面競爭力。
HKET App已全面升級,TOPick為大家推出一系列親子、健康、娛樂、港聞及休閒生活資訊及影片。立即下載︰https://onelink.to/f92q4m
追蹤TOPick Whatsapp頻道睇最新資訊︰http://tinyurl.com/3dtnw8f5
責任編輯:馮琪雅



